4.4.3 Batch Peak Analysis Using Theme with Script Before Each ProcessBatchPA-Script-Before
Summary
Origin can perform batch peak analysis of multiple datasets using an Analysis Theme. You can choose to pre-process the peak data (e.g., exclude unwanted datasets) before actually inputting data, by running a script before each process. Note that while Batch Peak Analysis Using Theme is not an OriginPro-only feature, this tutorial uses the Peak Analyzer Goal of Fit Peaks to create the Theme and Fit Peaks is a Pro-only feature.
Minimum Origin Version Required: 2016 SR0
What Will You Learn
This tutorial will show you how to:
- Save analysis settings as a theme for batch peak analysis
- Write script before each process to pre-process data
- Do batch peak analysis using an analysis theme
Steps
Save Analysis Settings as a Theme
This tutorial is associated with <Origin EXE Folder>\Samples\Tutorial Data.opj.
- Open Tutorial Data.opj and browse to the Script Before Process in Batch PA folder in Project Explorer (PE).
- Click on worksheet Data1 in the workbook. Highlight column B and go to menu Analysis: Peaks and Baseline: Peak Analyzer to open dialog. Select Fit Peaks(Pro) as Goal.
- Click Next button, select None(Y=0) as Baseline Mode. Click Next button twice to go to Fit Peaks(Pro) page, expand Configure Graph subnode under Result node and set Create Summary Graph to <None> to turn off generating report graph, which can speed up the analysis process.
- Now click the
 button next to the Dialog Theme control and select Save as ... to open Theme Save as... dialog. In the Theme Name edit box, enter MyPeakAnalysis and click OK button to save it. button next to the Dialog Theme control and select Save as ... to open Theme Save as... dialog. In the Theme Name edit box, enter MyPeakAnalysis and click OK button to save it.
- Click Finish Button to perform the analysis and output results.
Prepare Script for Pre-processing Peak Data
The Batch Peak Analysis Using Theme dialog provides three edit boxes to allow running script before each process, after each process and at the end of all processes. In this section we will mainly show how to write script before each process to pre-process the peak data.
- Activate worksheet Data1 again, we can see from the sparkline of each dataset that some of peak data are very noisy, e.g., column C, E, F, and we want to exclude such noisy dataset if it reaches certain noise level.
- The way used to identify whether data is noisy in this tutorial follows the routine below (if you don't see the Sparklines label row, right-click in the gray area to the right of your worksheet columns and enable by View: Sparklines):
- Filter raw data with a high-pass FFT filter to obtain the high-frequency noise from the data.
- Find the standard deviation(SD) of the noise and the corresponding raw data.
- Set a criteria that if the ratio of the square of SD of the noise over the square of SD of the raw data is over 30%, it will be regarded as noisy data and will be excluded for batch analysis.
- Follow the routine above, the script for pre-excluding noisy data is as following:
dataset dr;
fft_filters iy:=_ry filter:=high oy:=dr; // Perform high-pass fft filter to obtain noise
stats dr;
double nSD = stats.sd; // Calculate SD of noise
stats _ry;
double sSD = stats.sd; // Calculate SD of raw data
if(nSD^2/sSD^2>0.3) // Set noise identification criteria
_skip=1;
else
_skip=0;
where _ry refers to current y data, _skip determines whether to skip current dataset.
Batch Analyze Datasets Using Analysis Theme
- Activate worksheet Data1, highlight all columns in the sheet and go to menu Analysis: Peaks and Baseline: Batch Peak Analysis Using Theme... to open dialog.
- Select MyPeakAnalysis from Theme drop-down list, Peak Properties(Pro) from Result Sheet drop-down list.
- To output results to a specified sheet, you can enter the range syntax in Output Sheet edit box. Suppose we want to export to MyResults sheet in MySummary book, you can input [MySummary]MyResults! in the edit box.
- Input the script we wrote in section above into Script Before Each Process under Script node (Hint: Clicking the button to the right of the text box opens an edit box where you can paste and edit your script).
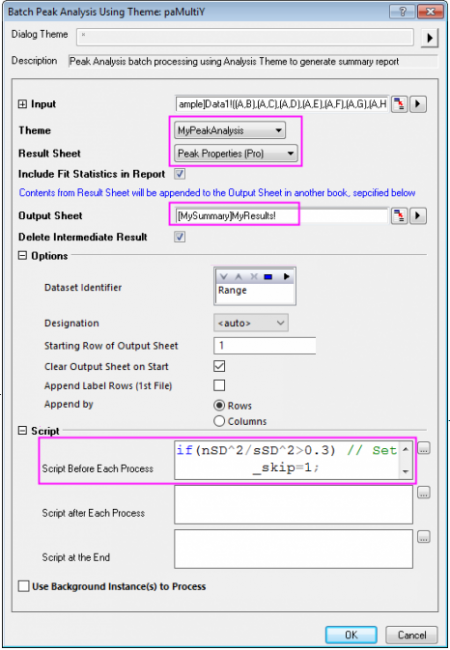
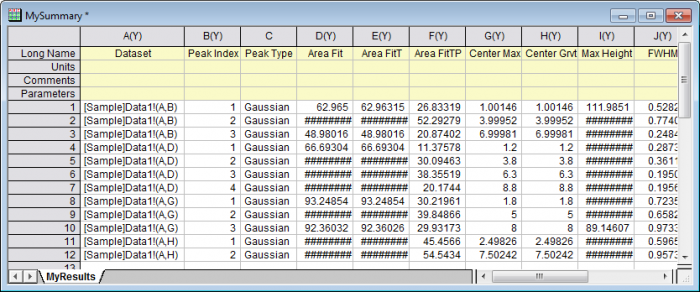
- Click OK button to perform batch peak analysis and you will see noisy datasets(say column C, E and F) are excluded in MyResults sheets.
|