Statistics
Origin provides a number of options for performing general statistical analysis including: descriptive statistics, one-sample and two-sample hypothesis tests, and one-way and two-way analysis of variance (ANOVA). Also, several types of statistical charts are supported, including histograms and box charts.
Advanced statistical analysis tools, such as repeated measures ANOVA, multivariate analysis, receiver operating characteristic (ROC) curves, power and sample size calculations, and nonparametric tests are available in OriginPro.
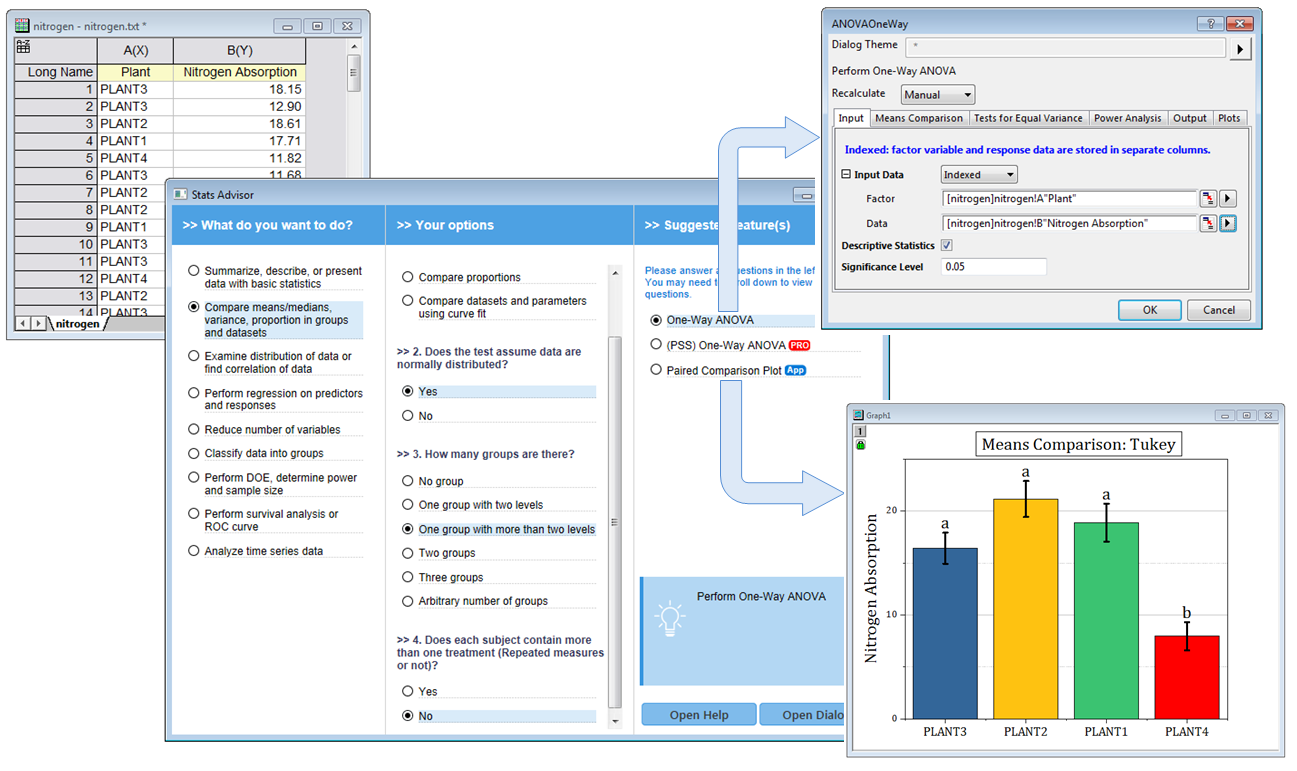
The Stats Advisor App asks a series of questions and then suggests the appropriate tool or App to analyze your data.
Descriptive Statistics
Origin provides the following tools to help you summarize your continuous and discrete data.
Descriptive
The Statistics on Columns/Rows operation performs column-wise/row-wise descriptive statistics on selected worksheet data.
Statistics on Columns
Performs column-wise descriptive statistics on grouped or raw data.
Statistics on Rows
Performs row-wise descriptive statistics to generate statistics for rows in worksheet.
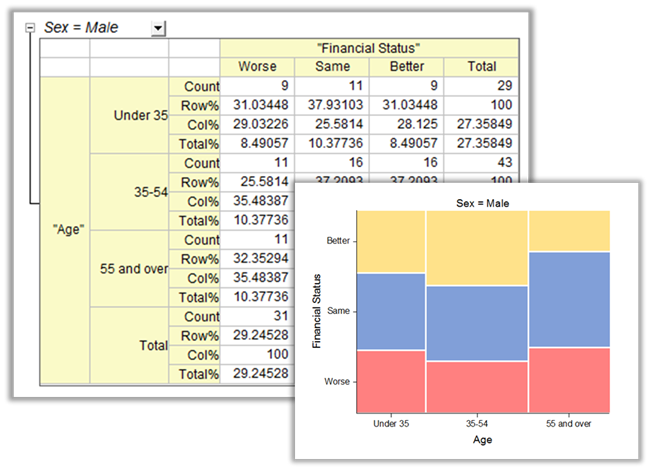
Cross tabulation(also known as contingency table) is a table to reveal the frequency distribution of the variables. The mosaic graph can be plotted in the report.
Cross tabulation (also known as contingency table) is a table to reveal the frequency distribution of the variables. Analysis based on the table can determine whether there is a significant relationship, obtain the strength and direction of the relationship, and measure and test the agreement of matched-pairs data. It is widely used to analyze categorical data.
Frequencies
Discrete Frequency
Discrete frequency analysis is one common method to analyze discrete variables. It counts the frequency of discrete data, including percentage and cumulative percentage.
Frequency Counts
This function computes the frequency counts for 1D data and helps produce histogram in desired way.
2D Frequency Count/Binning
A useful tool to compute the frequency counts and plot a 2D histogram for 2D/bivariate data.
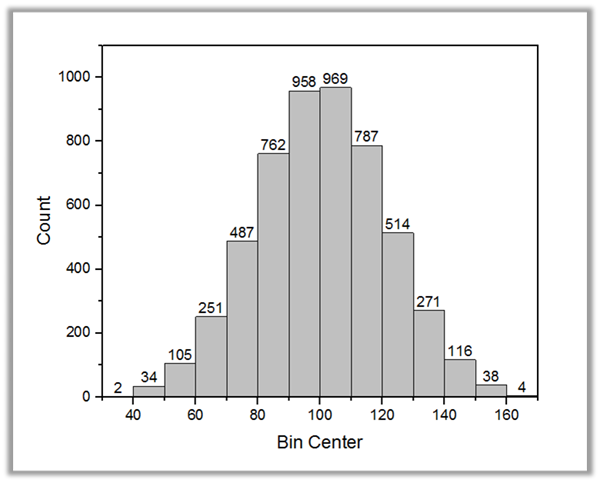
The Frequency Counts
tool is to measure the number of times a value is encountered that falls within each bin for a range of data. Then the results can be used to generate a histogram which allow more customization such as label on top of bars or having uneven bin size ect.
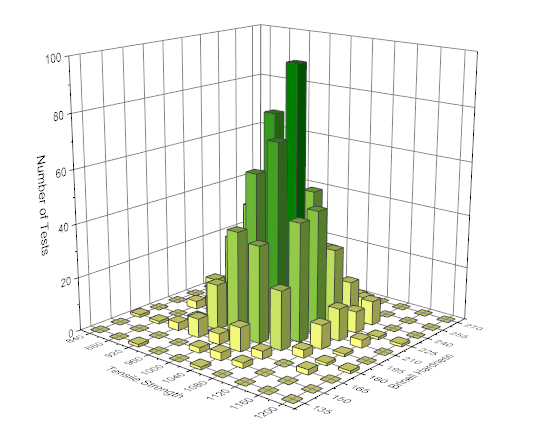
The 2D Frequency Counts/Binning tool is similar to the Frequency Counts but for two-dimension variables. With the tool, we can generate 2D histogram to visually detect the distribution for 2D data.
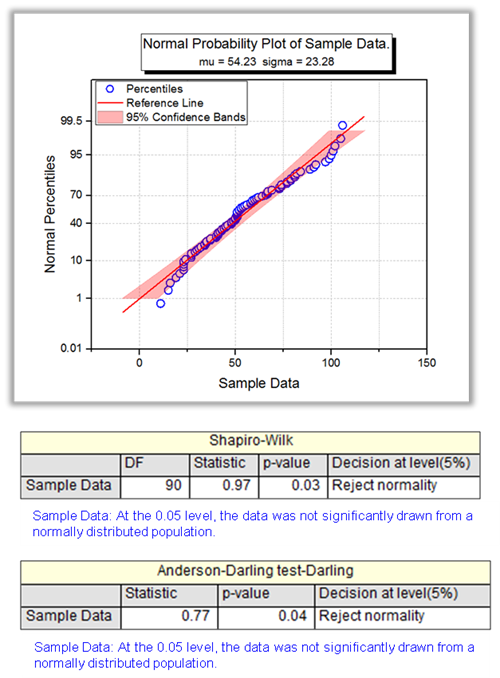
Use Normality Test to determine whether data has been drawn from a normally distributed population (within some tolerance). Origin supports six methods for the normality test, Shapiro-Wilk, Kolmogorov-Smirnov, Lilliefors, Anderson-Darling, D'Agostino's K-Squared and Chen-Shapiro
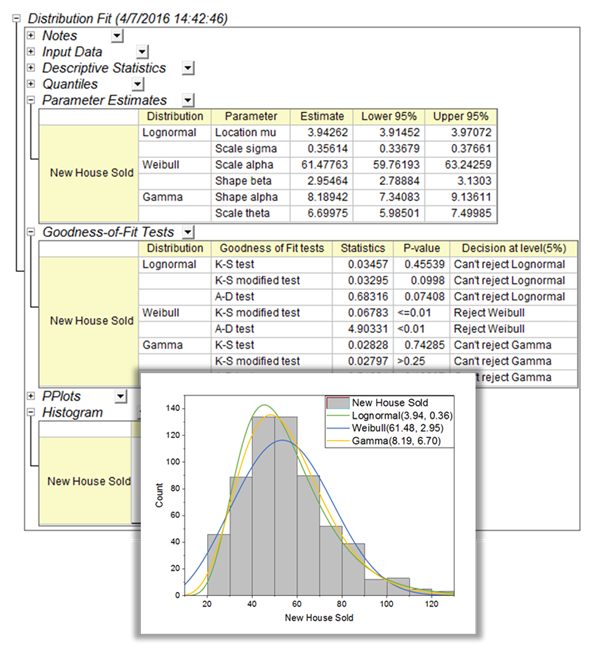
The Distribution Fit tool helps users to examine the distribution of their data, and estimate parameters for the distribution
Normality Test
A normality test is used to determine whether sample data has been drawn from a normally distributed population (within some tolerance).
Six different normality tests are available in Origin:
- Shapiro-Wilk
- Kolmogorov-Smirnov
- Lilliefors
- Anderson-Darling
- D'Agostino's K-Squared
- Chen-Shapiro
Distribution Fit PRO
Knowing the distribution model of the data helps you to continue with the right analysis, or make an estimation of your data. The Distribution Fit tool helps users examine the distribution of their data, and estimate parameters for the distribution
Correlation Coefficient PRO
Correlation Coefficient PRO
The correlation coefficient, also called the cross-correlation coefficient, is a measure of the strength of the relationship between pairs of variables. Origin provides both parametric and non-parametric measures of correlation.
- Pearson's r Correlation
- Spearman's Rank Order Correlation
- Kendall's tau Correlation
Partial Correlation Coefficient PRO
Partial correlation measures the linear relationship between two random variables, after excluding the effects of one or more control variables.
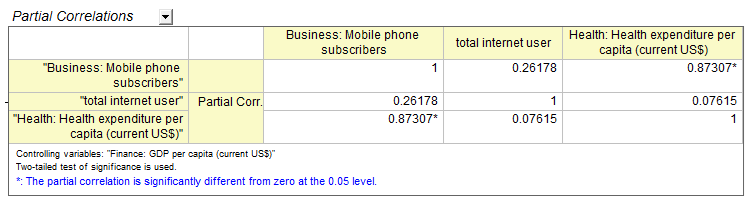
The Partial Correlation tool measures the linear relationship between two random variables, after excluding the effects of one or more control variables.
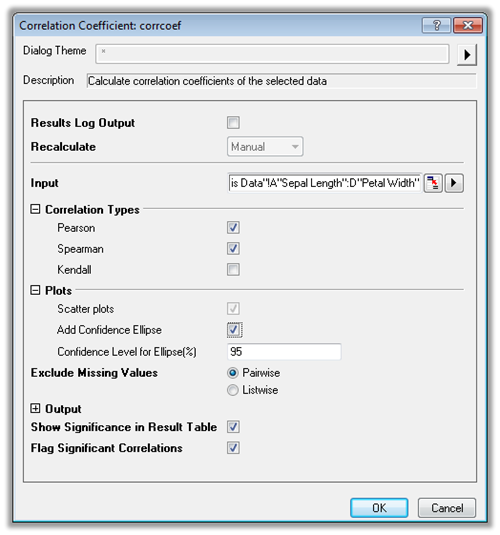
The image displays the Dialog of Correlation Coefficient tool in Origin. The tool supports three tests, Pearson's r Correlation, Spearman's Rank Order Correlation and Kendall's tau Correlation. And user can choose whether to flag the significant correlations in result
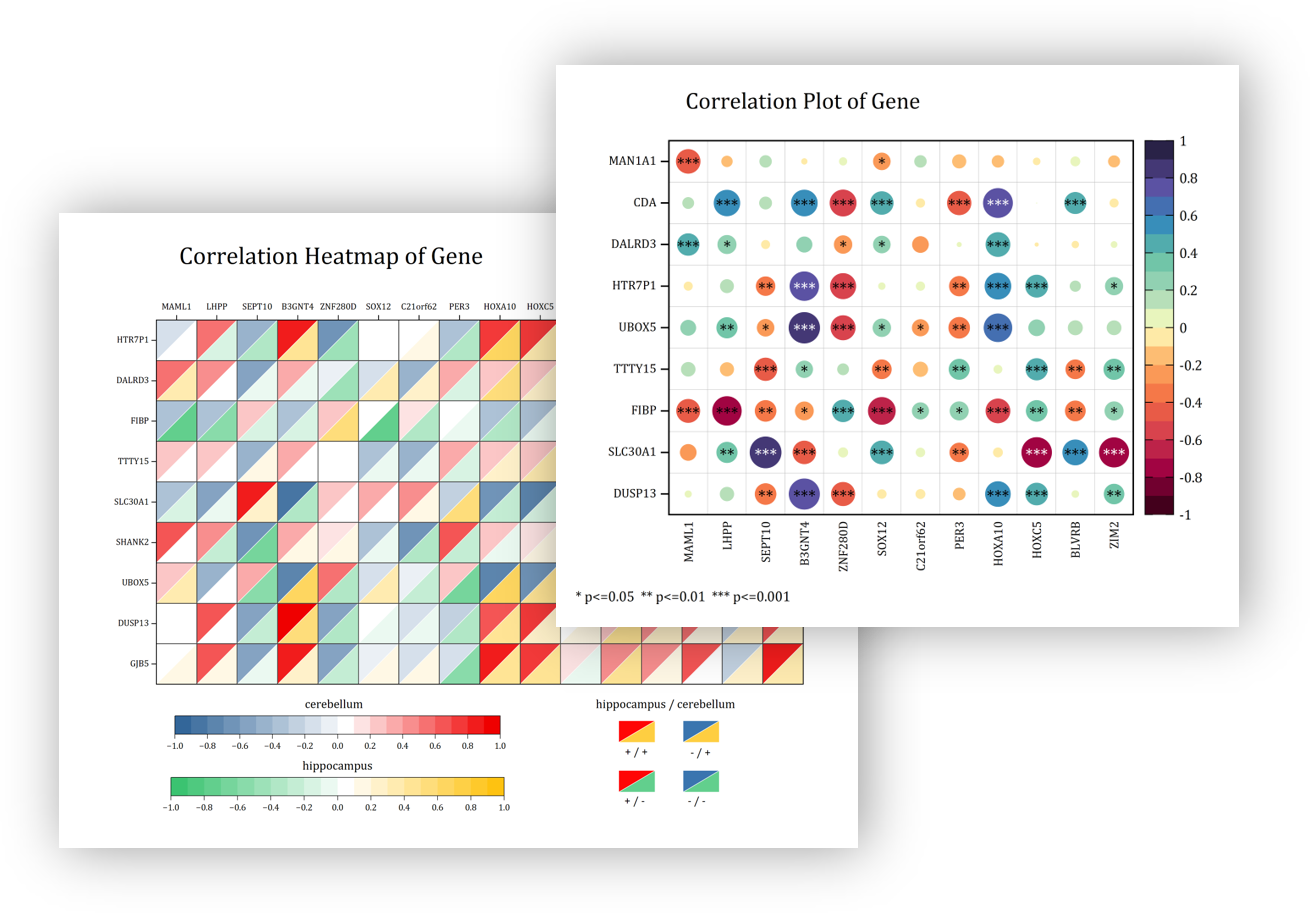
Visualize the correlation coefficients with various correlation plots in Origin
Detecting Outliers
An outlier is an observation that is dramatically distant from the rest of the data. Origin provides two tools to help detect the outliers.
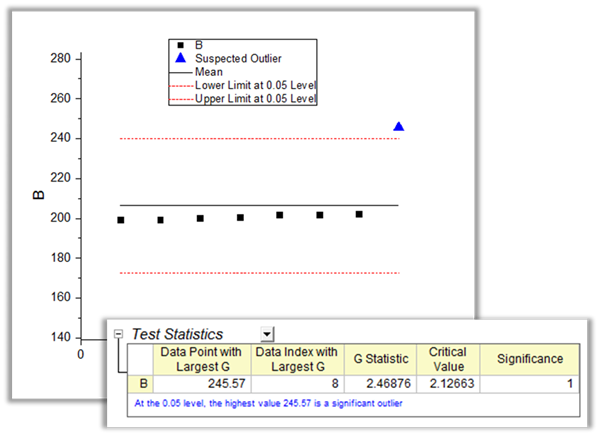
Two tools in Origin can be used to detect outliers in data, Grubb's Test and the Dixon's Q-test. The outliers plot in the tools can help user to visually judge how the outlier is distant from other observations.
Regression
In addition to curve fitting for numeric data, Origin also supports various regression tools in the statistical area:
- Linear Regression
- Logistic Regression
- General Linear Regression
- Poisson Regression
- Best Subset Selection
- Nonlinear Regression
General Linear Regression
The General Linear Regression app enables users to build models that include main effects, interactions, and higher order terms.
Key Features
- Flexible Model Specification
- Stepwise Regression
- Optimizer Tool
- Comprehensive Coefficient Estimates
- Robust Fit Statistics
- Extensive Model Diagnostics
- Graphical Analysis
- Prediction and Forecasting
Best Subset Selection
With Origin’s intuitive interface, easily tailor your model using the built-in options:
- Force the inclusion of key predictors
- Control model complexity by specifying the minimum and maximum number of predictors
- Filter results to show only the best models that meet model evaluation criteria such as:
- adjusted R2
- PRESS
- Mallow’s CP
- Root MSE
- AICc
- BIC and more
- Seamlessly run a Multiple Linear Regression once the best model is identified
Logistic Regression
Origin’s Logistic Regression tool supports classification analyses that include Binary, Multinomial, and Ordinal Response Variables.
Flexible modeling options with support for:
- Continuous and categorical predictor variables
- Interaction terms to capture complex relationships
- Choice of link functions under Ordinal logistic regression:
- Logit
- Probit
- Negative log-log
- Cauchit
Easily toggle options to show:
- Odds ratios and their 95% Confidence Intervals
- Classification tables to evaluate prediction accuracy
- Correlation and covariance matrices of model predictors
- Influential data points displaying high-leverage cases
- Residual plots for model diagnostics
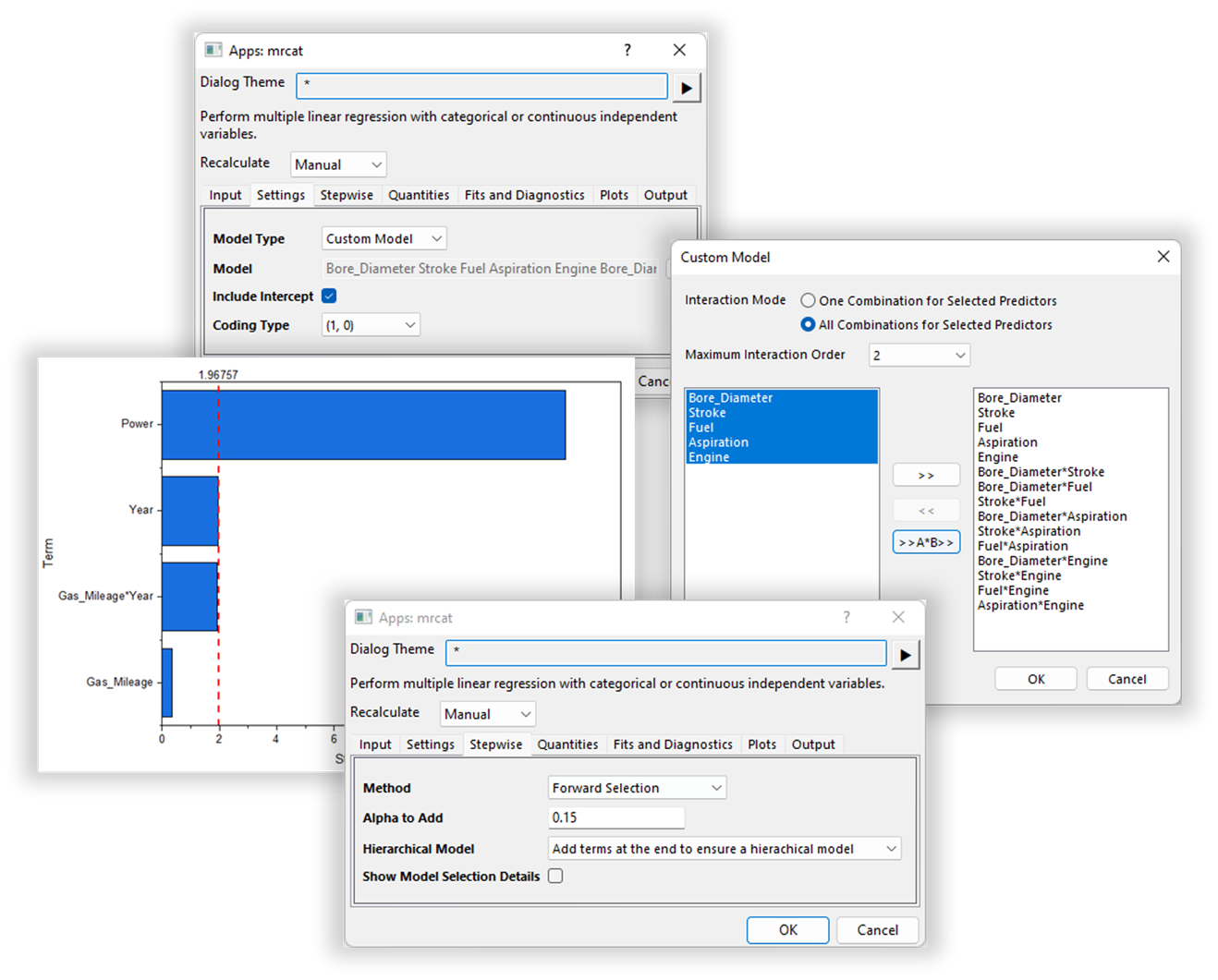
The General Linear Regression tool enables users to build models that include main effects, interactions, and higher order terms.
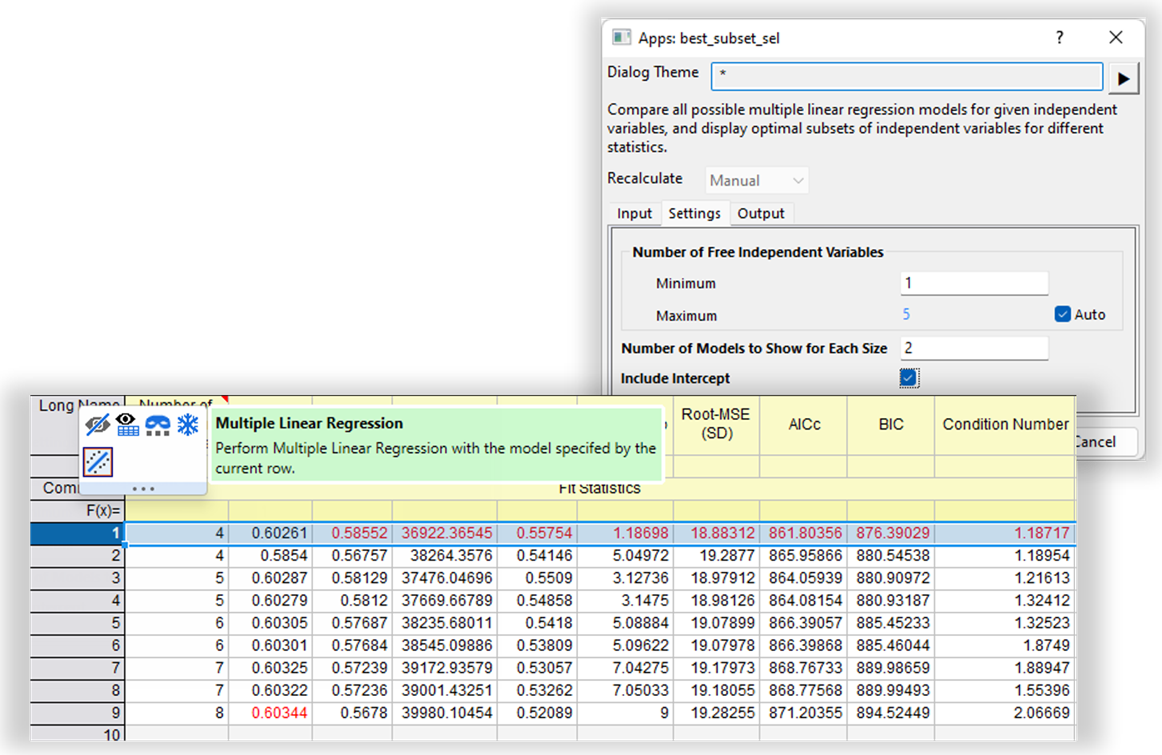
Seamlessly run a Multiple Linear Regression once best model is identified using Best Subset Selection tool
ANOVA
Analysis of variance (ANOVA) is used to examine the differences between group means. In addition to determining that differences exist among the means, ANOVA tools in Origin provide multiple means comparisons in order to identify which particular means are different.
One-Way, Two-Way, and Three-Way ANOVA
One-way, two-way, and three-way ANOVA consider a completely randomized design for an experiment.
One-Way ANOVA
One-way ANOVA compares three or more levels within one factor.
Two-Way ANOVA
Two-way ANOVA is useful to compare the effect of multiple levels of two factors. Two-way ANOVA is an appropriate method to analyze the main effects of and interactions between two factors.
Three-Way ANOVA PRO
Three-way ANOVA tests for interaction effects between three independent variables on a continuous dependent variable (i.e., if a three-way interaction exists).
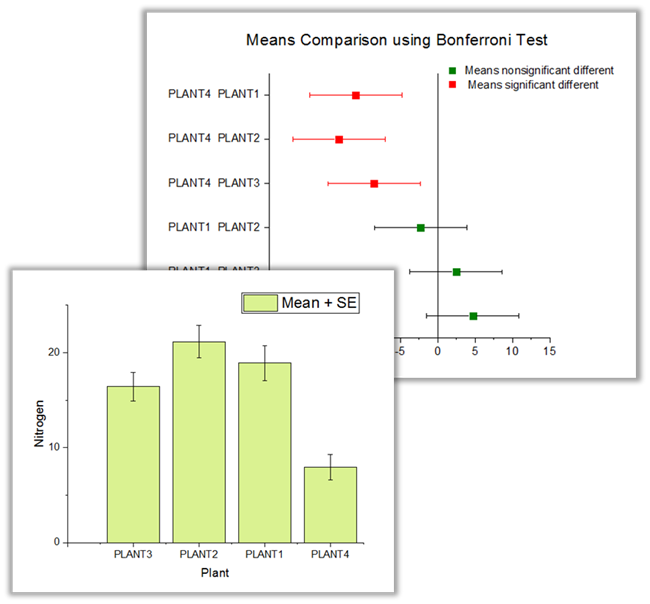
The graph displays the Mean+SE plot and Means comparison plot in one-way anova. They are help to visually compare multiple groups, determine whether their means are different.
Repeated Measure ANOVA PRO
The repeated measures design is also known as a within-subject design. It has the same subjects performed under every condition.
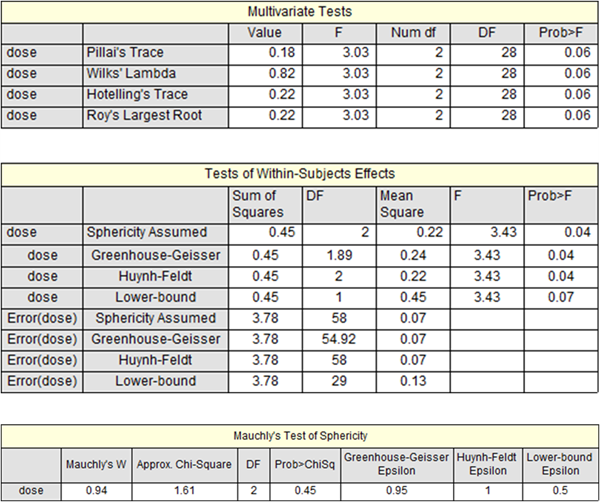
The repeated measures ANOVA is used for comparing three or more means when all subjects are measured under a number of different conditions.
Repeated measure ANOVA tools in Origin consider three possible designs:
- One-way Repeated Measures PRO
ANOVA with one repeated-measures factor.
- Two-way Repeated Measures PRO
ANOVA with two repeated-measures factors.
The two-way mixed-design is also known as two-way split-plot design (SPANOVA). It is ANOVA with one repeated-measures factor and one between-groups factor.
One-Way and Two-Way MANOVA PRO
Multivariate Analysis of Variance (MANOVA) is a statistical technique used to analyze the differences between group means across multiple dependent variables simultaneously.
One-Way MANOVA PRO
Compare the means of multiple dependent variables across different levels of a single independent variable (factor).
- Multiple Dependent Variables
- Comprehensive Statistical Output
- Post-Hoc Comparisons
Two-Way MANOVA PRO
Extends the concept of One-Way MANOVA by allowing the analysis of the effects of two categorical independent variables (factors) on multiple continuous dependent variables.
- Dual-Factor Analysis
- Comprehensive Statistical Output
- Post-Hoc Comparisons
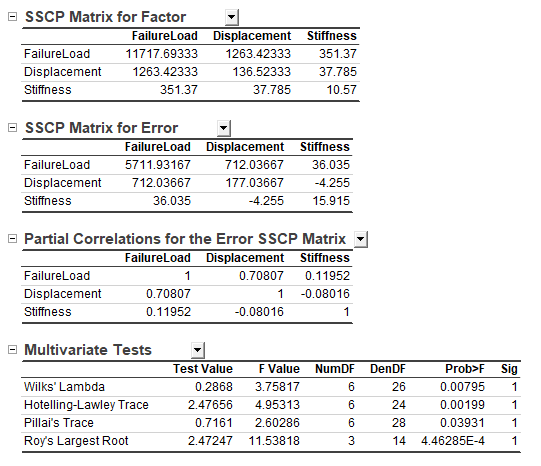
The result of One-Way MANOVA
Means Comparison / Post-hoc Tests
The mean comparison tests in ANOVA, also known as Post Hoc tests, are useful to perform additional comparisons of subsets of the means.
All four ANOVA tools in Origin, one and two-way ANOVA, one and two-way repeated measure ANOVA, provide seven means comparison tests:
- Tukey
- Bonferroni
- Dunn-Sidak
- Fisher LSD
- Scheffé
- Holm-Bonferroni
- Holm-Sidak
Linear Mixed Effects Models PRO
Linear Mixed Effects Models (LMMs) are powerful statistical tools used to analyze data with hierarchical or nested structures.
- Fixed and Random Effects
- Flexible in Model Specification
- Robust Model Diagnostics
- Support for Complex Data Structures
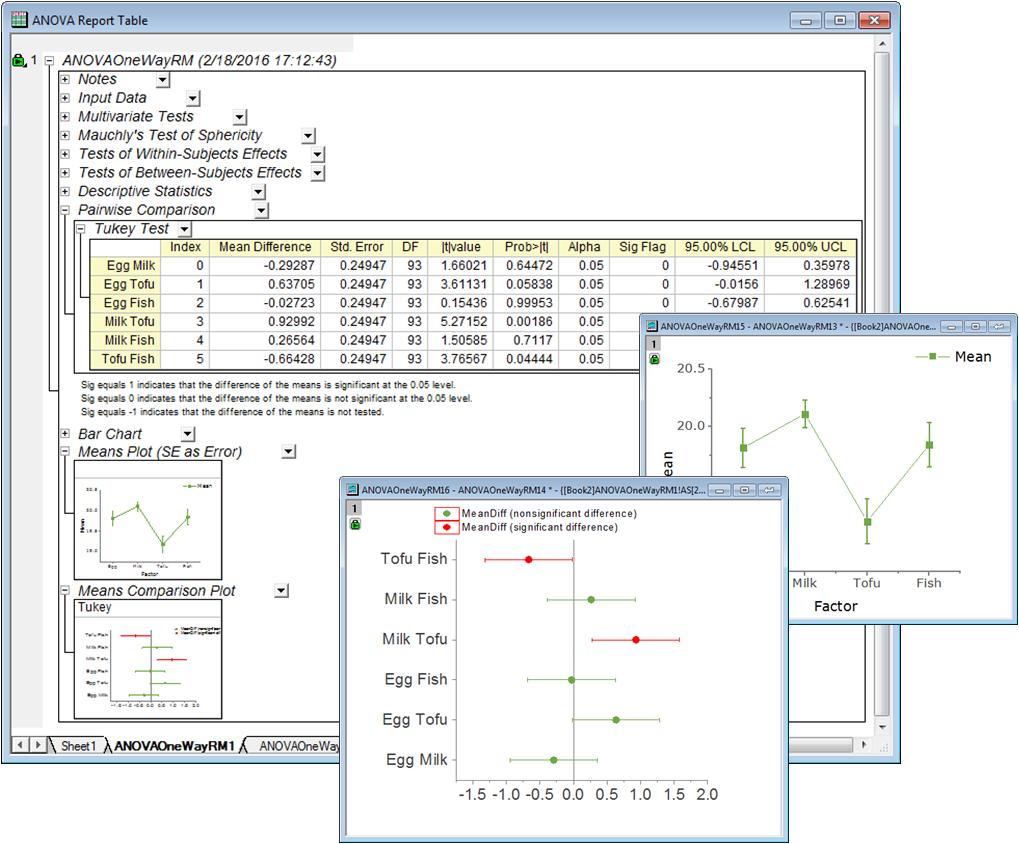
An Origin Analysis Report Sheet, this one created by the One-way Repeated Measures ANOVA tool. The image shows two of the embedded graphs opened for further editing. Edit an embedded graph by double-clicking on the thumbnail image in the report. Once customizations are made, put the graphs back into the report and see your modifications.
Parametric and Nonparametric Testing
Parametric Tests
T-Tests for Means
- One-Sample T-Test
- Pair-Sample T-Test
- Two-Sample T-Test
T-Tests on Rows PRO
- Pair-Sample T-Test on Rows
- Two-Sample T-Test on Rows
Variance Tests PRO
- One-Sample Test for Variance
- Two-Sample Test for Variance
Proportion Tests PRO
- One-Sample Proportion Test
- Two-Sample Proportion Test
Power and Sample Size PRO
The following testings are available:
- (PSS)One-Sample t-Test
- (PSS)Two-Sample t-Test
- (PSS)Paired-Sample t-Test
- (PSS)One-Way ANOVA
- (PSS)One-Proportion Test
- (PSS)Two-Proportion Test
- (PSS)Two-Variance Test
Nonparametric Tests PRO
Analyze data without making any assumptions about the underlying distribution of the data.
One-Sample
- Wilcoxon Signed Rank Test
Paired Samples
- Wilcoxon Signed Rank Test
- Sign Test
Two Samples
- Mann-Whitney
- Kolmogorov-Smirnov Test
Multiple Independent Samples
- Kruskal-Wallis ANOVA
- Mood's Median Test
Multiple Related Samples
Post-hoc Analysis for Multiple Samples
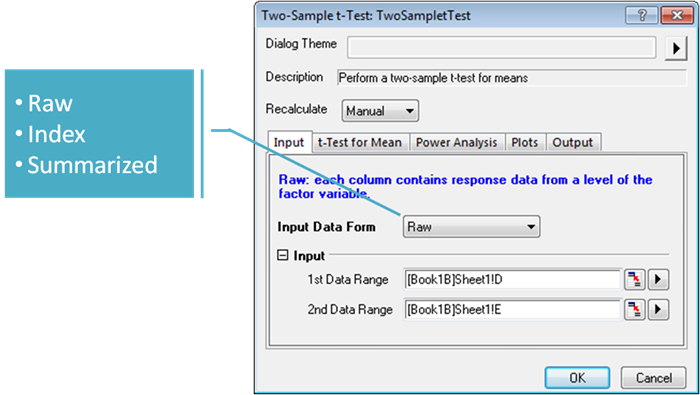
Origin supports different input mode for hypothesis testing. User don't need to transform their data before using the tools.
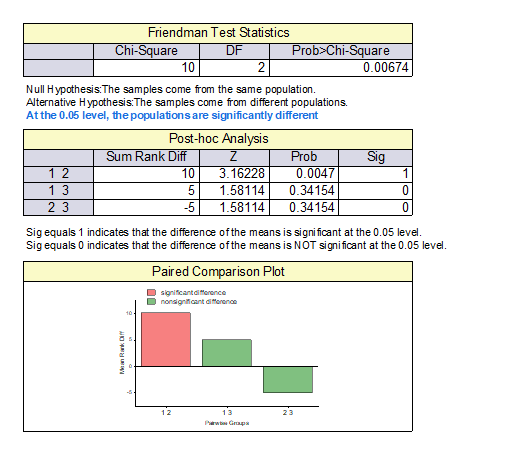
Results of Friedman ANOVA with post-hoc analysis and paried comparison plot
Quality Control and Improvement PRO
Statistical methods for quality control and improvement involve the use of collected data and quality standards to find new ways to improve products and services. These methods characteristically involve attempts to infer the properties of a large collection of data.
Statistical Process Control (SPC)
Control Charts
- Xbar-R
- Xbar-S
- I-MR-R/S
- I-MR
- Z-MR
- P/U Chart
- Moving Average
- EWMA
- CUSUM
Capability Analysis
- Capability Histogram
- Cp, Cpk, Cpm, Pp, Ppk
- Performance Report
- Normal/Non-normal/Attribute
Process Overview
- Normal Process
- Between/Within Process
- Non-normal Process
Measurement System Analysis (MSA)
Gage R&R Study
- Type 1 Gage Study
- Gage Linear Bias Analysis
- Crossed Gage R&R Study
- Nested Gage R&R Study
- Expanded Gage R&R Study
- Attribute Gage Study
- Create Gage Worksheet
Attribute Agreement Analysis
- Kappa Statistics
- Kendall's Coefficient of Concordance
- Within Appraisers Analysis
- All Appraisers vs. Standard Analysis
- Agreement Graphs
- Confidence Intervals
- Misclassification Rates
Tolerance Interval
- Normal and Non-normal distributions
- Parametric and non-parametric tolerance intervals
- Sample size & Maximum Population Percentage in Interval
- Graphical report including interval plot, histogram, and probability plots
Design of Experiments (DOE)
Power and sample size
- Decide the sample size or power for the experiment
Design
- 2-level factorial
- Plackett-Burman
- General full factorial
- Central composite
- Box-Behnken
Analysis
- Linear+ Interaction+Square models
- Analyze design with stepwise
- Goodness-of-fit
- Fits and residual diagnostics
- Find Y from X
Graphics
- Fitted Plot
- Residual Plot
- Effects Plot
- Main Effects Plot
- 2-way Interaction Plots
- Contour Plot
- Surface Plot
Optimize
- Optimize the process conditions to achieve the desired result
Read More>>

The results of Gage R&R Study in Origin include a combination report with graphical analysis and a report sheet with ANOVA table, variance components and Gage R&R statistics
Time Series Exploration and Analysis PRO 
Origin provides the following Time Series tools to help users explore, visualize, and analyze their time series data:
Smooth
- Moving Average
- Single Exp Smoothing
- Double Exp Smoothing
- Winter's Method
Correlation
- Autocorrelation
- Partial Autocorrelation
- Cross Correlation
Spectral Analysis
Univariate or Bivariate
- Daniell Method
- Lag Window
ARIMA Model
Stationary Test
Trend
- Trend Analysis
- Time Series Decomposition
Differences & Lag
Read More>>
Survival and Reliability Analysis PRO
OriginPro includes the following widely used tools for survival and reliability analysis:
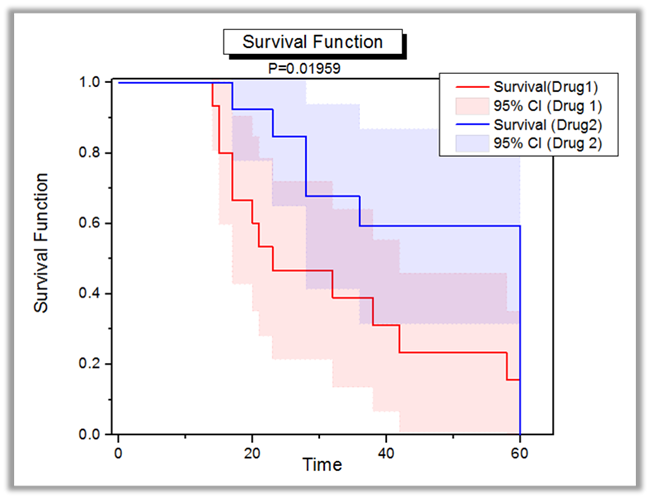
The graph displays the survival function plot in Kaplan-Meier Estimator. A log-rank test is perform to compare the two survival function.
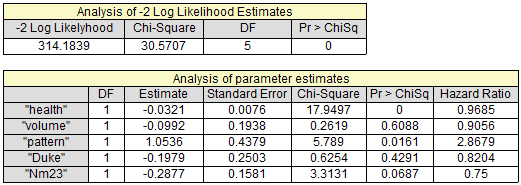
The image displays a part of reports of the Cox Proportional Hazard Regression, which is a semi-parameter method to forecast changes in the hazard rate along with a variety of fixed covariates.
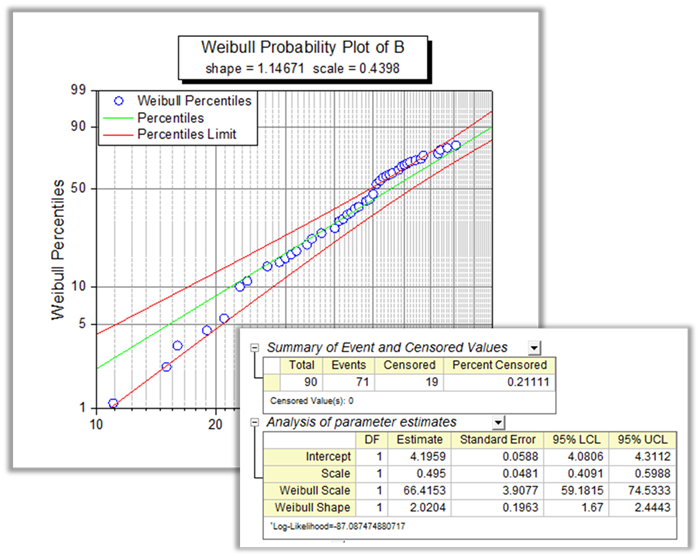
The Weibull Fit is a parameter method to analyze the relationship between the survival function and the failure time. User can see the parameter estimation of the Weibull model from the result table and visually decide whether the data are drop from Weibull distribution from the Weibull Probability Plot
Kaplan-Meier Estimator PRO
Kaplan-Meier Estimator, a non-parametric estimator, uses product-limit methods to estimate the survival function from lifetime data.
In addition to estimating the survival functions, Kaplan-Meier Estimator in Origin provides three other methods to compare the survival function between two samples:
- Log Rank
- Breslow
- Tarone-Ware
Cox Proportional Hazard Model PRO
The proportional hazards model, also called Cox model, is a classical semi-parameter method. It relates the time of an event, usually death or failure, to a number of explanatory variables known as covariates.
Weibull Fit PRO
Weibull fit is a parameter method to analyze the relationship between the survival function and the failure time. We suppose that the survival function follows a Weibull distribution and fit the model with a maximum likelihood estimation.
Probit Analysis PRO
The Probit Analysis tool can be used to examine the model of the relationship between a binary-response variable and a continuous-dose variable, to fit a probit sigmoid dose-response curve and calculate values (with 95% CI) of the dose variable that correspond to a series of probabilities. The tool in Origin provides the following features:
- Binary-Response Modeling
- Maximum Likelihood Estimation
- Graphical display of estimated probit regression equation
ROC Curve PRO
ROC (Receiver Operating Characteristic) curve analysis is mainly used for diagnostic studies in Clinical Chemistry, Pharmacology, and Physiology. It has been widely accepted as the standard tool for describing and comparing the accuracy of diagnostic tests.
For example, you can use ROC Curve analysis to test a diagnostic to determine if an incident had occurred, or compare the accuracy of two methods that are used to discriminate diseased cases versus healthy cases.
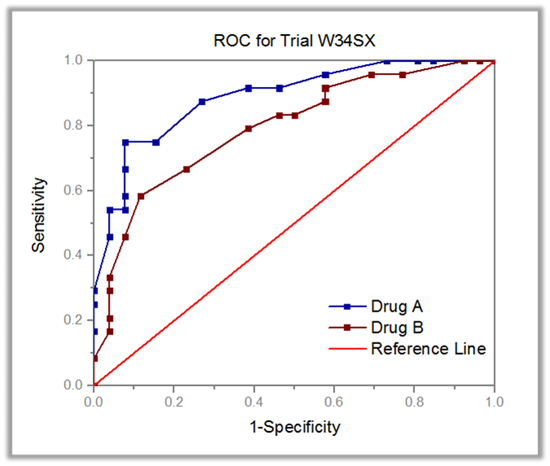
The ROC Curve analysis can be used to test a diagnostic to determine if an incident had occurred, or compare the accuracy of two methods that are used to discriminate diseased cases versus healthy cases.
Machine Learning PRO
Machine learning is a method of data analysis that learns information directly from data to automate analytical model building. The machine learning algorithms learn from data, identify patterns, and make decisions.

Origin provides various machine learning tools to help you investigate your data.
Multivariate Analysis PRO
Multivariate analysis is a set of techniques used to analyze data that corresponds to more than one variable. The main objective of this analysis is to study how the variables are related to one another, and how they work in combination to distinguish between multiple cases of observations.
Principal Component Analysis PRO
Principal Component Analysis (PCA) is used to explain the variance-covariance structure of a set of variables through linear combinations of those variables. PCA is thus often used as a technique for reducing dimensionality.
Cluster Analysis PRO
Cluster analysis is used to construct smaller groups with similar properties from a large set of heterogeneous data. This form of analysis is an effective way to discover relationships within a large number of variables or observations.
Hierarchical PRO
In this method, elements are grouped into successively larger clusters by some measures of similarity or distance.
K-means PRO
Use K-means clustering to classify observations through K number of clusters.
Faster than Hierarchical, but user needs to know the centroid of the observations, or at least the number of groups to be clustered.
Discriminant Analysis PRO
Discriminant analysis is used to distinguish distinct sets of observations, and to allocate new observations to previously defined groups.
Partial Least Squares Regression PRO
Partial Least Squares regression (PLS) is used for constructing predictive models when there are many highly collinear factors.
There are two primary reasons for using PLS:
- Prediction
PLS is most commonly used for constructing predictive models when the information is contained in a large number of original variables that are highly collinear.
- Interpretation
PLS can be used to discover important features of a large data set. It often reveals relationships that were previously unsuspected, thereby allowing interpretations of the data that may not ordinarily result from examination of the data.
Decision Tree Analysis PRO
Origin offers a tool for decision tree analysis that allows users to create a binary decision tree to solve classification problems for a binomial or multinomial categorical response with multiple continuous and categorical predictors.
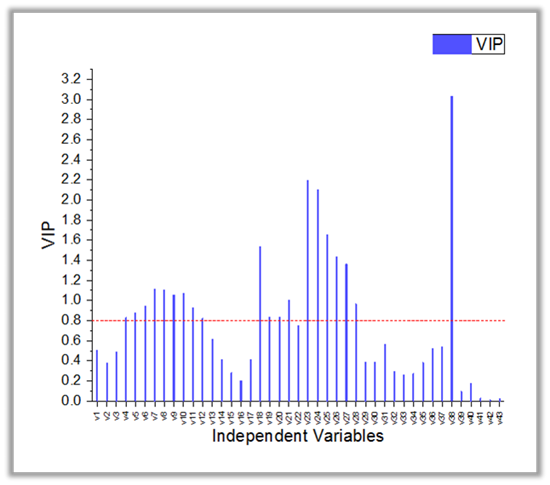
The Partial Least Squares in Origin is used for constructing predictive models when there are many highly collinear factors. The Variable Importance Plot can help to judge the importance of each variable.
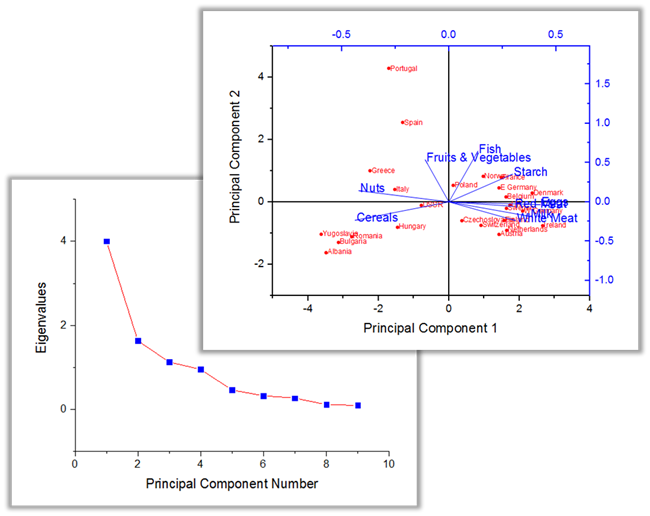
The Principal Component Analysis (PCA) tool is used to explain the variance-covariance structure of a set of variables through linear combinations. The scree plot is a useful visual aid for determining an appropriate number of principal components. And the Loading and Score plot can be used for interpreting relations among observations and variables.
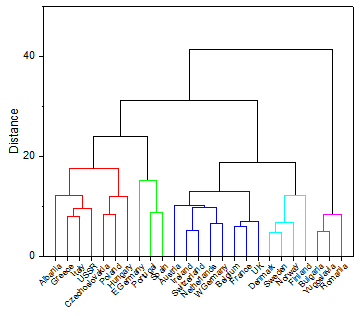
A Dendrogram plot created by the Hierarchical Cluster Analysis tool, which can be used to list all samples and indicates at what level of similarity any two clusters were joined
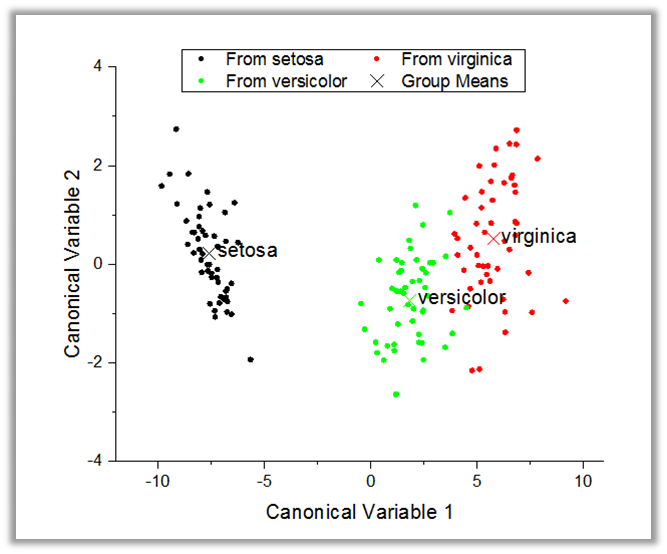
A Canonical Score Plot created by the Discriminant Analysis tool in OriginPro. This plot can be used to classify observations across groups.
Apps
Extend the statistics functionality of Origin by installing free Apps from our File Exchange site. Below is a selection of statistics Apps:
Find More Apps>>